



OpenAI brings new AI image generation directly to GPT-4o
OpenAI unveils advanced image generation in ChatGPT and Sora


OpenAI has introduced powerful new AI image-generation capabilities into ChatGPT and Sora, powered by its cutting-edge GPT-4o model.
This upgrade enables users to generate and edit images directly within the chat interface, eliminating the need for external tools like DALL-E…
…or Midjourney. 😬
With GPT-4o’s multimodal capabilities, users can now:
Create new images from scratch using natural language prompts.
Edit existing images, including those featuring people, while maintaining realism and scene complexity, again, with natural language prompts.
Upload and modify files within ChatGPT, streamlining the image creation process.
It may not sound like much, but it is. This is big.
The Age of Multimodal AI Tools is here.
First it was Gemini 2.0 Flash. Now OpenAI.
Chatting with your Image Generator (and soon, Video Generators) will be a basic requirement from now on.
When was the last time you had a chat with Midjourney?
Here's what you need to know:
Users can generate/edit images using natural language or uploaded files.
GPT-4o understands what you ask from it, leveraging its vast knowledge to understand context better, leading to better and more relevant high-quality visuals.
Its multimodal capabilities allow it to generate more accurate text rendering and better integration of images within conversations.
As it understands text and images, it can generate structured visuals like menus, diagrams, and infographics with readable text, addressing a key limitation of previous models.
Image editing has been improved, allowing modifications to existing images while accurately handling complex scenes with up to 20 distinct objects. It can see the image, analyze it, and understand your request.
The updated image-generation abilities are now available to ChatGPT Free, Plus, Team, and Pro users.
So, it is good?
Let’s see some examples. Consider the following: Each one of these requires an understanding of the context, something previous image generators can’t do.
1. Studio Ghibli-style memes
Users quickly discovered the tool can transform regular photos into artwork mimicking the whimsical, hand-drawn aesthetic of Studio Ghibli films. People jumped on this, turning everything from selfies to memes into Ghibli-esque scenes, and it’s taken off across social media, especially on platforms like X.

2. Fictional Movie Posters
@thekitze shared this poster on X.

3. Web Screenshots
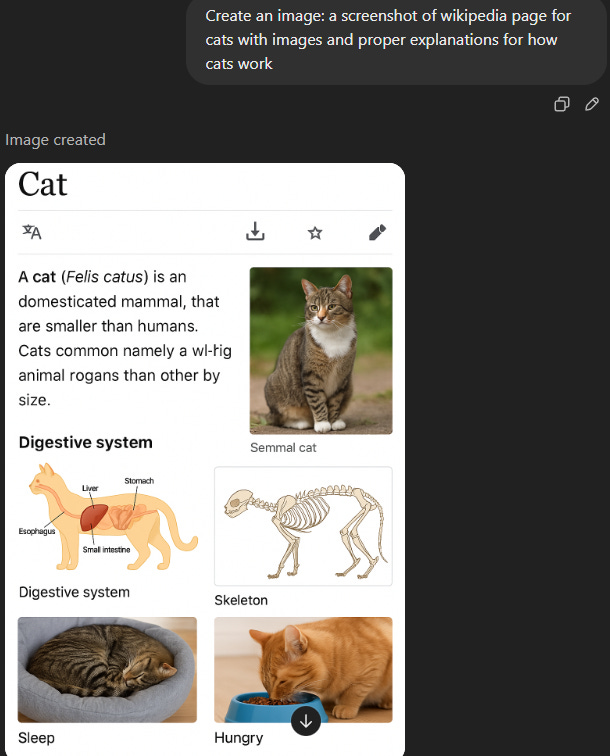
4. Extract assets from images

5. Voxel Art

6. Comic Stories

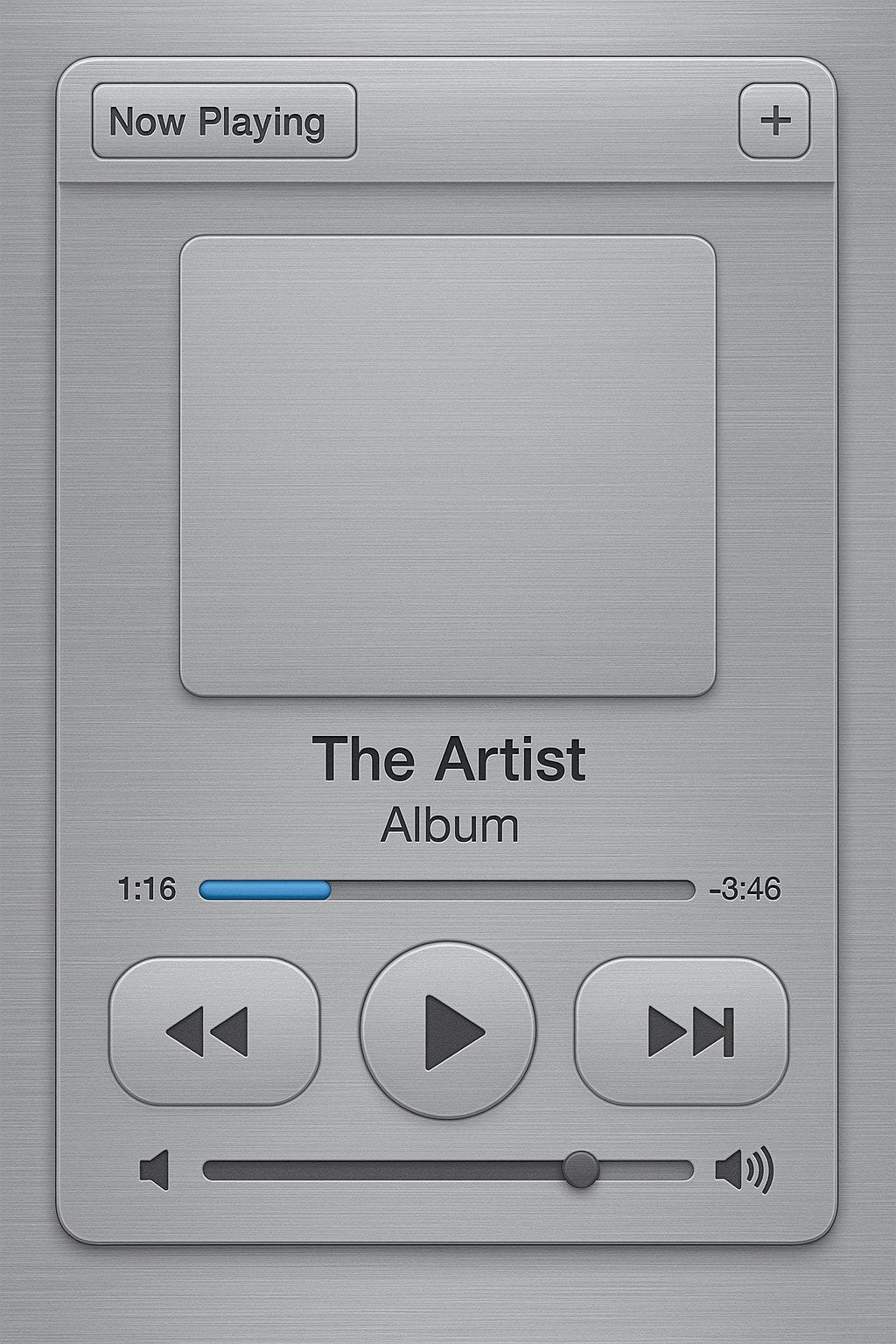
7. UI Designs
8. Marketing Ads

So, what do you think? Is it good? is it hype?
Can you do things like character and style references in ChatGPT? This is one thing that makes me use Midjourney over DALL-E based images as I can keep consistency very high. Even asking GPT to tweak an image (in past experience) results in other changes that I never asked for.